7.5.14 MCU ramdump 功能
目前 MCU0/MCU1的 Crash 信息共享一块内存。MCU0/MCU1同时出现异常的情况下,MCU ramdump 功能保存的信息不可用。
概述
MCU ramdump 功能的开发,主要是为了 mcu 在发生 crash 或进入异常时,能打印异常信息并将这些信息进行保存,便于我们分析定位出现异常的位置。
异常处理流程
当 MCU 进入异常时候,MCU 会将现场信息保留在一个全局变量中,该全局变量可以被 acore 读取,也可以通过 MCU shell 读取。
如果是 MCU0出现异常,系统将会重启,系统重启流程中会判断重启原因。如果判断重启原因是mpainc,系统会确保保存 MCU 异常现场信息的全局变量对应的内存空间不清0,我们可以在系统重启后读取到 ramdump 的数据,并基于此来分析异常发生的原因。
异常处理流程如下所示:
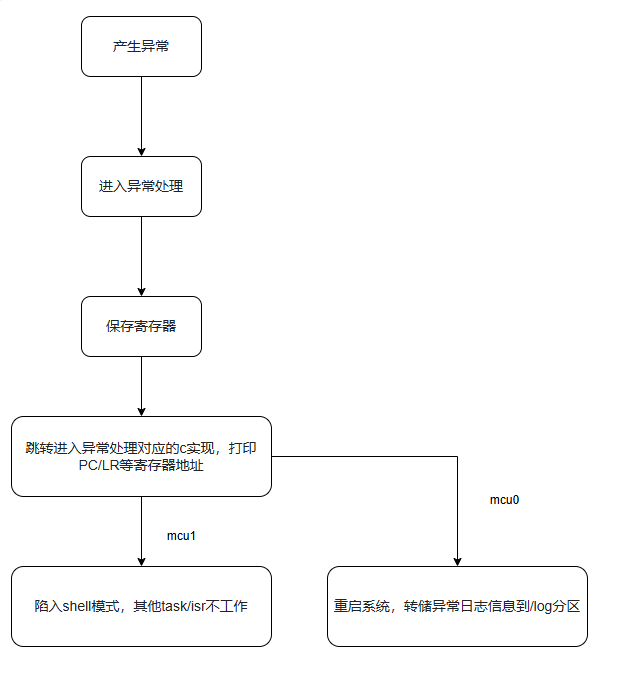
MCU0和 MCU1的异常处理流程基本类似,区别只在于 MCU0在处理异常后会重启系统。
异常后重启 MCU1
MCU1出现异常后会陷入 shell,这时可以通过 acore remoteproc 控制机制停止以及重新启动 MCU1。命令�参考如下:
# 停止运行
echo stop > /sys/class/remoteproc/remoteproc_MCU0/state
# 启动
echo start > /sys/class/remoteproc/remoteproc_MCU0/state
获取 MCU 异常信息
-
可以在 acore 通过 sysfs 节点读取 MCU1异常时记录的现场信息。对应的 sys 节点信息如下:
cat /sys/devices/platform/soc/soc:mcu_crash/crash -
MCU0发生异常,系统重启后检查重启原因是 mpainc,会将现场信息转储到
/log分区,便于我们跟踪历史日志分析问题。log 日志转储目录命名格式如SuperSoC_Mdump-<count>-<time>。
其中,<count>代表系统第几次重启。<time>代表时间,时间格式:“年_月_日_时_分_秒”,例如:SuperSoC_Mdump-0010-2025_08_13_20_25_11 -
mcu 在发生 data abort/undefined/prefetch 异常时,可以将现场信息 dump 出来,便于我们分析问题。
异常打印分析
以发生 data abort 为例记录的异常信息进行说明:
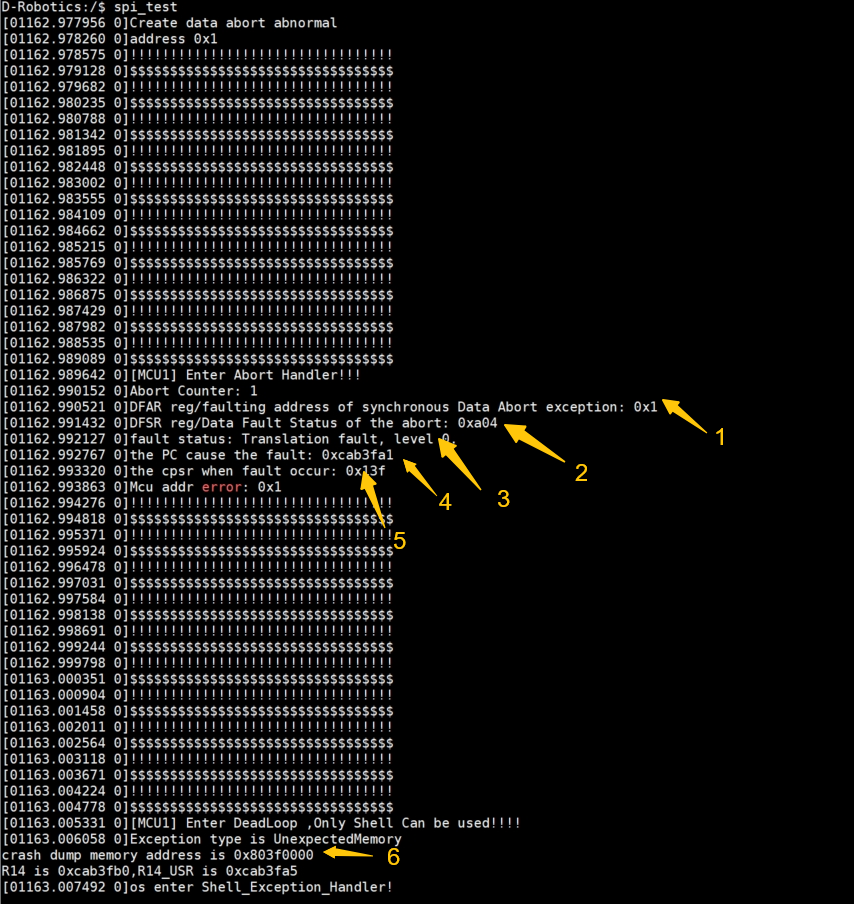
这些数据的含义如下:
-
箭头1表示出现数据访问异常时的访问地址,如上图可以看到异常的时候,是尝试访问0x1地址的数据
-
箭头2是异常状态的数据,一般可不关注
-
箭头3表示发生的异常类型
-
箭头4表示产生异常的指令所在位置。通过该地址信息我们结合 elf 解析,可以定位到发生异常时的具体代码位置。示例如下:
addr2line -e S100_MCU_DEBUG.elf 0xcab3fa1如果系统没有安装 addr2line,可以通过以下命令安装:
sudo apt update
sudo apt install binutils -y -
箭头5表示产生异常时,CPU cpsr 寄存器的值
-
箭头6表示发生异常时记录 crash dump 的地址信息。可以通过 MCU shell 输入
dumpmem [addr] 4 64来读取 crash 现场保存的寄存器和栈信息,或者在acore通过sysfs获取 crash 现场的寄存器和栈信息